分步式文件存储系统技术及实现
姚文辉
阿里云大学提供的关于分布式存储的实现细节。
[TOC]
1. 分布式存储客观需求
分布式存储系统
- 大数据对分布式存储的需求
- 分布式存储系统架构
- 分布式存储系统重要的功能剖析
- 元数据服务器的高可用性和可扩展性
- 多种介质的混合存储系统
大数据对分布式存储的需求
要对1PB数据排序,我们需要什么样的存储系统?
存储量(>100PB)
吞吐量(1PB<2H)
Gray
需求点:
存储容量大
搞吞吐量
提高数据可靠性(99.9999999%)
服务高可用(99.95%)
高效运维
将日常硬件处理作为常态,做成流程化
对于监控、报警等机制也要有非常完善的支持
低成本
存储系统的核心竞争力
保证数据安全、正确服务稳定的前提下降低成本,才是分布式存储的核心竞争力。
2. 小概率事件对分布式系统的挑战
大规模分布式存储的挑战
单机(桌面)系统 –> 小概率出错
大规模存储 –> 小概率事件成为常态
概率论:小概率事件一定发生
哪些小概率事件会发生?
磁盘错误
发现慢节点就自动规避
发现机器宕机自动绕过
Raid卡故障
发生在集群里面的高可用节点
在我们的存储系统中存放Meta
延迟100-200us
网络故障
电源故障
可能会导致MemCache丢数据
如果数据丢失,怎么去恢复数据
数据错误
磁盘
网络
内存
使用CRC校验对数据进行全链路保护
系统异常
Linux系统相对稳定,但是本身的机制可能会引起一些异常
- 时钟源 – 存在时钟跳变的问题
- memcache刷数据存在问题,会影响其他磁盘
热点
软件缺陷
误操作
关键目录进行保护,设置为不可修改/不可删除
3. 常见分布式系统
常见分布式系统
HDFS
Ceph
Pangu
其他
GPFS
Lustre
MooseFS
4. 分布式设计要点
读写流程
Qos (服务质量)
Checksum (文件正确性)
Replication (复制)
Rebalance (平衡)
Garbage Collection (GC)
Erasure Coding (成本相关)
5. 分布式系统功能设计-写入流程
链式写入流程
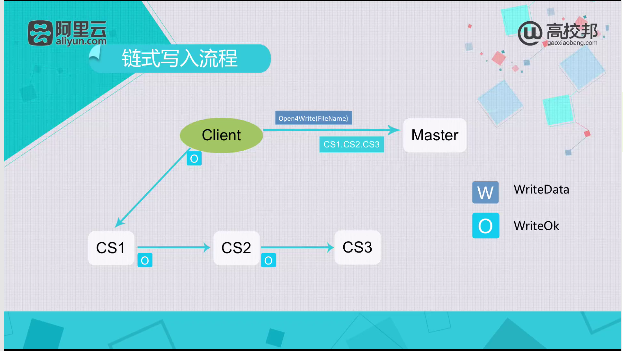
作用:有利于从集群外部导入数据到集群内部,网络流量充分被利用。
弊端:会产生三段网络的延迟
组从模式
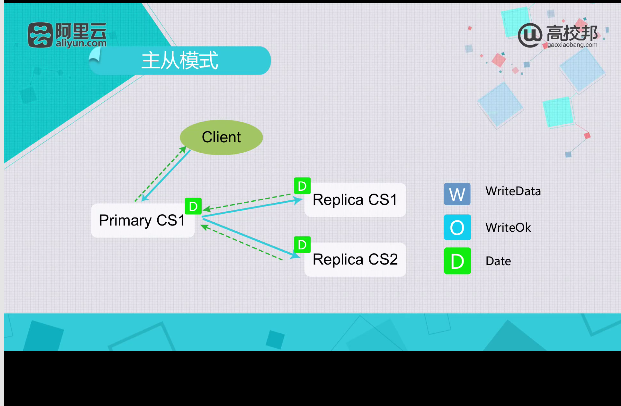
减短了传递的延迟
使用辐射发包方式,导致Primary网络最高利用率是1/2,对于流量较高的应用是不合适的。
对于流量较低的应用较合适。
链式异常写入流程
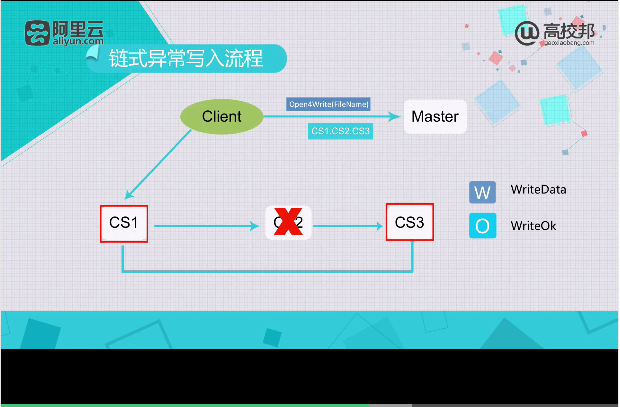
降低数据安全性
保证数据成功率
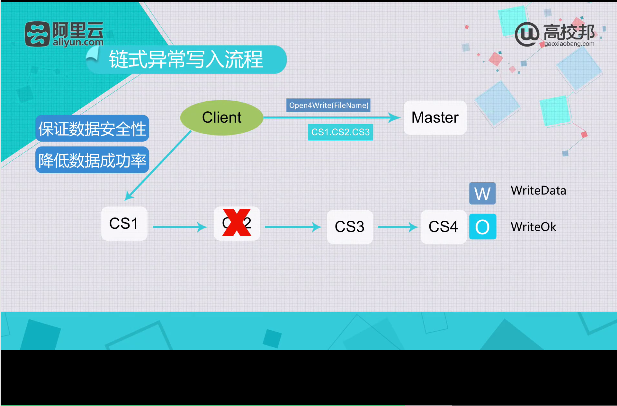
保证数据安全性
降低数据成功率
Seal and New
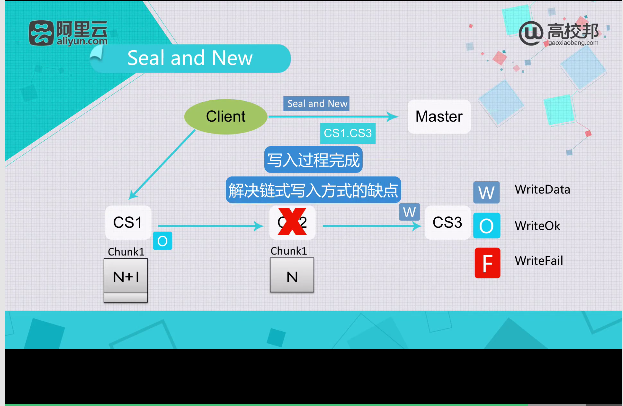
数据写入流程总结
| 数据写入方式 | 优点 | 不足 |
|---|---|---|
| 链式写入 | 每个节点负载和流量比较均衡 | 链条过长,出现异常时诊断和修复过程比较复杂 |
| 主从写入 | 总路径较短,管理逻辑由主节点负责 | 主节点由可能成为负责和流量瓶颈 |
不同的应用场景,使用不同的写入方式
| 异常处理方式 | 优点 | 不足 |
|---|---|---|
| 重新修复 | 最大程度保留之前写入的数据 | - 直接剔除异常节点会导致后续写入的replica数降低 / - 如果补充新的replca进来,需要补齐之前写入的数据给新的replica |
| Seal and New | 简单快速,可以绕过异常节点 | Chunk长度不固定,需要更多的meta管理 |
6. 分布式系统功能设计-读取流程
BackupRead 解决慢节点
发起多个请求,可以把慢节点完全规避掉。在平均延迟都增大的情况,会出现问题。
读流程优化-规避慢节点
有效地发现集群中最快的节点
可有效规避慢节点,对集群中的热点做到动态规划
多个副本分布方式:
可读取任意有效副本
副本出现异常时尝其他副本
Backup Read可减少读取延迟
根据局部性原理,选取最优副本访问
7. 分布式系统功能设计-QoS
按优先级划分IO
区分用户
8. 分布式系统功能设计-Checksum
CRC校验
全链路保护

